
I started converting some of my hobby projects using Codex to Go exactly month ago, and developing two iOS apps after initial honeymoon period with Codex CLI was done (I felt it to be good enough in the trial conversion effort).
Here’s some notes of my experiences and a bonus rant near the end..
My thoughts about Codex CLI and OpenAI models in general
Overall it has been pretty good. While they are clearly iterating on how e.g. sub-agents work, the basic flow is pretty robust. It is annoying that you cannot use separate model for planning and build stages though - just different thinking levels. I have wound up using ‘high’ for planning and ‘medium’ for implementation for most part, most recently using GPT 5.4.
While I have used Claude extensively in the past, I don’t feel MOSTLY too bad about using the GPT models for coding either.
Spark was available for a bit (but seems not to be available anymore, or perhaps my configuration breaks it somehow), and while it was fast, it was also very inefficient way to code - multiple iterations for even small stuff, so while the iterations were fast, I am not sure if it was really worth it as the overall implementation time with the retries was not substantially faster, and sometimes the result quality was still worse.
Notable problems with the models or agentic harness
There is perhaps half dozen cases during the month when Codex got basically stuck, unable to resolve the problem, and I had to figure it out on my own how to fix it either manually or give Codex exact prompts on how to fix things. However, in general, it was quite smooth sailing.
Here are two examples of where I needed to think on my own (quite a bit, as it turns out):
SwiftSoup memory leak
When writing my news reading app, I wound up using SwiftSoup as a library to parse and rewrite the HTML on pages I retrieved ( scinfu/SwiftSoup: SwiftSoup: Pure Swift HTML Parser, with best of DOM, CSS, and jquery (Supports Linux, iOS, Mac, tvOS, watchOS) ). However, try as much as I could, the app kept leaking lots of memory. Codex did not figure it out at all, and despite me pointing out that e.g. Element and Document objects were consuming orders of magnitude more memory than they should (e.g. 80 GB instead of megabytes), it could not resolve it.
I looked at it bit myself, tried to help the code with some prompts (as I saw there were reference cycles going on), but despite bunch of weak self insertions to the closures and handful of other attempts, I simply could not fix the leak. So in the end I went for Plan B, I just told Codex to switch to https://github.com/kylehowells/swift-justhtml library instead. Memory usage went to ~100-200MB, and I was happy. Except for half day playing with Instruments and trying to understand the gnarly code, of course.
iOS iCloud use
When writing another app, I spent half day trying to get files upload to iCloud. Codex did dozen attempts, making the code more and more convoluted and weird, but in the end it boiled down to two problems that I figured on my own:
- initially entitlements were wrong (this I figured quite rapidly)
- the name of the bundle that I was using was just
XXX. When I changed it tofi.fingon.XXXit worked fine. (Both were registered to my app, but for some reason at least on-device files browser as well as finder on Mac did not show the just XXX).
How much did it cost?
First off, looking at the API token usage costs, it would seem to be quite expensive hobby:
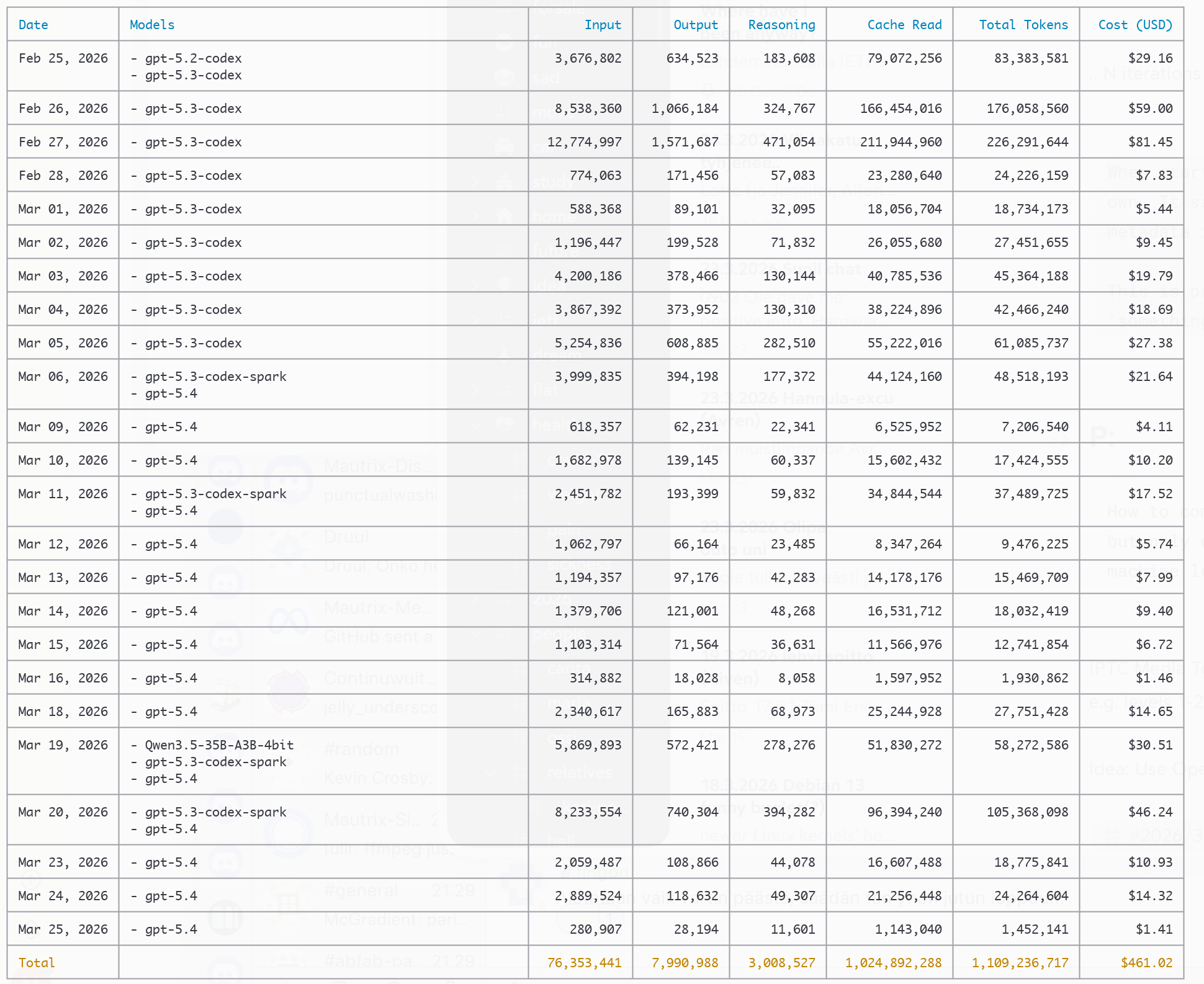 .. crazy. While there were some usage resets at some point (mostly in early February and March I think), you get crazy amount of tokens for the subscription pricing, which was 20€ for the period - about 95% discount.
.. crazy. While there were some usage resets at some point (mostly in early February and March I think), you get crazy amount of tokens for the subscription pricing, which was 20€ for the period - about 95% discount.
What did I get out of it?
- https://github.com/fingon/proprdb - third iteration of my ‘personal stuff database’ (this time using Go, protobufs and JSONL) - 3,4k LoC
- ( not yet published) - Go conversion of my old Python life logging tools; I may publish it someday - 26k LoC (which uses ^ for data storage)
- iOS app 1 - start of RSS reader app - 12,1k LoC
- iOS app 2 - for private use for now - 17,6k LoC
This is 59.1k LoC of actual code + tests that are in the final version. There were many, many iterations. There are 20-50 commits in each of those repos, and quite many of them rewrites as I figured better ways to do things. But now I have replaced my old Python life log tools to Go, they work, and I also have 1,5 apps that also work (the RSS reader needs bit more visual design and I will actually make it available).
Would I do it again?
Probably. I hear Claude subscription is not as good a deal, and I definitely like some aspects of Codex CLI (it is written in Rust, and open source). In some ways it is lagging behind OpenCode, but I enjoy using it well enough I suppose.
Bonus rant: ‘Agentic coding improves coder productivity by 10%’
Back in my peak days (which are probably in distant past by now), I considered 1k LoC of code and tests that compiled, and did not have obvious bugs, a good days work. I have worked on the above ~60k LoC during perhaps 15-20 days, and definitely not full time (fire off the agent, do something else, get back to it, test, iterate, and repeat - and sometimes run out of ChatGPT quota and think on something else or play with OpenCode), and assuming 50% of working and 17.5 days, this is about 9 days of active work at most. So the productivity multiplier is about 6.6x for me, give or take little (perhaps bit less, as some of the stuff LLM produces is not necessary, or is overly elaborate).
The nature of work is quite different too - you need to think more about what you plan to do, and less about the details. Of course, sometimes you decide that details the model went for are wrong and then you iterate, but I think perfectionism is definitely the enemy of ‘good enough’ here. Whether ‘good enough’ is enough for all cases, is of course open to debate. Using vibe coded health device would feel scary, but random app that doesn’t touch money? It is probably ‘fine’.
Having both unit tests and some sort of smoke test for the rest (e.g. ‘does it compile’?) seems critical, but given that is in place (and I have learned by now to start my every LLM assisted exercise with it), the results seem good enough. And you can use tests (and-or co-written documentation about scarier parts) to reason if the implementation is doing what you actually want.
Final thoughts
I started coding ‘something’ in 1984, in Basic, on C64. While I enjoyed manual coding literally 40 years, by 2024 I started dabbling little with using LLMs for coding, as they seemed to be somewhat valuable then as smarter autocomplete mechanism, and last year I already realized I am not going back.
While designing algorithms and things in general is the more interesting part of programming, the low level ‘insert lots of syntax in, get result out’ is not something that excites me and LLMs allow me to skip it altogether and focus more on the outcomes and less on the programming language surface syntax.
Doing this same thing with local models isn’t really reasonable (I dabble with them constantly, but the results are slower to produce and of inferior quality), but perhaps some day that will be possible too. Until that, I am going to pay for compute in the cloud (or use free stuff where reasonable) to get results faster than I could otherwise.
