
I have been using pyinfra for various things at home (and work) for a while now (since December 2021). There has been 700+ commits in the repository called ‘pyinfra’, and all of them are actually done by hand (old-fashioned, I know). Oddly enough, this is the only repository (besides my Obsidian vaults) that I have both been actively using this year AND is so far completely LLM free.
I have had separate repositories for at-work use, but this post isn’t going to detail any of that.
What do I do with it?
A lot. All of my computers - laptops, servers, or other toys like Raspberry PIs - have their core configuration there. It also orchestrates frankenrouter’s IaC configuration (which includes about 40 different containers), cloud VPSes, as well as my home k3s Kubernetes cluster nodes (bit more containers).
What don’t I do with it? (or, Pulumi in Pyinfra repo)
For the time being, I am still using Pulumi to manage the Kubernetes resources, my Oracle VPS nodes (but not its configuration), and also Cloudflare DNS records for my home. That is subset of the ‘pyinfra’ repository just because I like having single IaC repository, though:

Go code is leftover of my Pulumi Go use - my Oracle VPS setup is still set up with that (I prefer Pulumi Python these days, as if you are going to compile Go anyway and still have it fail dynamically when running, why not just write more concise Python to start with)?
I used to be more optimistic about using Go with Pulumi (c.f. Pulumi (and pyinfra) at home), but nowadays I like my infra defined in Python. Why?
- It is fast to ’try if it runs’
- Type safety isn’t usually the biggest problem - the biggest problem is something you typically cannot verify locally, but instead depends on what the code does to the actual resources it manipulates
How much code is the whole repo?
Quite a bit, considering it has been written by hand, but not a lot by modern LLM creation standards:
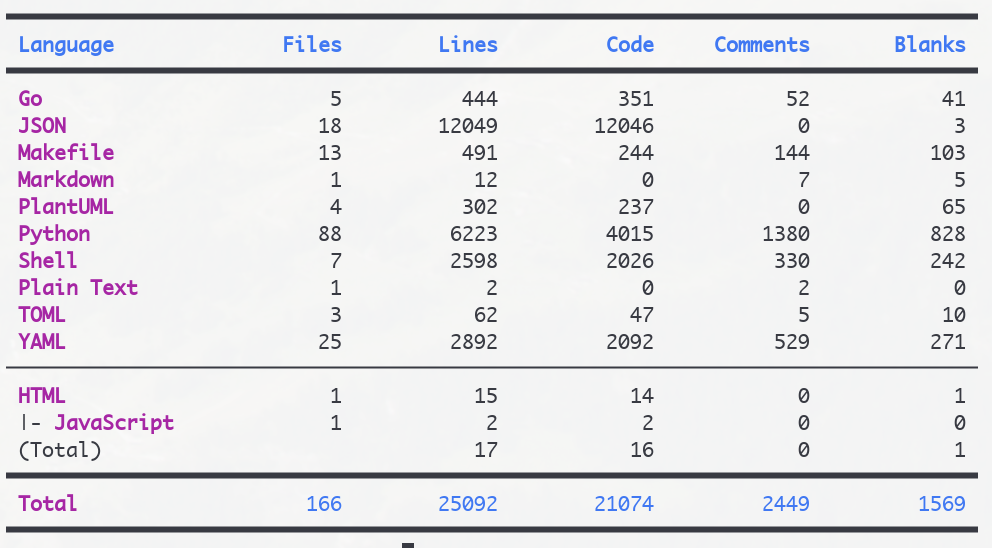
Thoughts about the numbers:
- JSON is mostly Grafana dashboards that I back up to the repo, as well as Caddy and Vector configurations’ JSON versions (which are easier to deal with software than the source format they are in)
- PlantUML I should probably do more - but I’ve nowadays switched to mostly using Monodraw for beautiful(?) ASCII art instead
- I have simply git rm’d anything I don’t use - most recently Garage S3 storage as I switched to Versity S3 Gateway instead - the actual code amount is probably order of magnitude mode over the years
My happiness level with the current state of affairs?
I give it a solid 8 out of 10. While it works, and I can easily do configuration changes to almost 100 containers (and almost dozen machines), a lot of it feels like kludge on top of kludge.
For example, most of frankenrouter podman containers are defined as single pyinfra file, which mostly just calls one or two Python utility functions, which set up or manages the container as systemd service on frankenrouter. It mostly works, except removing services is bit painful:
- rm symlink to the pyinfra file in the machine-specific subdirectory
systemctl disable --user --now containernameon frankenrouter- (optionally) delete the data or IaC code if I am giving up on that particular kind of container altogether
For that something stateful like Pulumi would work a lot better. But Pulumi is already slow with my k3s setup with way fewer resources, and I’m not really optimistic about scaling it any further.
What would I like to see?
‘Pulumi, but better’ (for me, at any rate)
- default mode: assume state is same as what is out there, just do changes
- less ugly Python bindings
With it, ideally, I would just say ‘give me container X at node Y’, and once I want to get rid of it, everything on the node would be deleted (if not marked protected somehow; perhaps the data could be protected by default).
Currently my Pulumi Kubernetes setup does it, but it is a lot more verbose so friction for using it is a lot compared to just using pyinfra.