As noted before, I have used kind (Kubernetes in Docker) in home for a while just as Docker compose replacement (and to tinker with some Kubernetes-only tools at home). For a while I have wanted something I could upgrade, and in general HA, and kind is not that.
So I bought some hardware (see earlier post). Then I setup some software (this post).
What did I want? I wanted HA tinfoil hat cluster, in other words:
- highly available compute
- highly available encrypted storage
- no plaintext traffic between cluster nodes
I have been thinking about it since April, and I finished the build in June. Here is an overview of some choices I made when I was building it.
Operating system: Ubuntu 24.04 LTS
I wanted something Debian based mostly because I like it. I looked hard at zfs (root) on Debian, but the guides involved large number of manual steps, and I try to do as few manual steps as possible when provisioning machines, so it did not feel ideal.
Ubuntu on the other hand actually offered zfs provisioning out of the box. I used cloud-init with following configuration:
#cloud-config
autoinstall:
version: 1
storage:
layout:
name: zfs
identity:
hostname: ubuntu-server
password: <<omitted>>
username: mstenber
ssh:
install-server: yes
and I was off to the races. Or at least, the start of the race, as it netted me server nodes with zfs on root, and no other configuration, but that’s what pyinfra is for (and I have plenty of Debian/ubuntu IaC configs I could reuse anyway).
I am not sure I am big fan of Ubuntu ‘Pro’, but as I have only 5 Ubuntu nodes, it is free, so I can live with using it. Supposedly it nets me bit better security updates than the non-‘pro’.
How to encrypt storage on server nodes: zfs + sss-memvault
zfs has reasonably good encryption support. However, I did not like the existing options for storing encryption keys:
- prompt for key (yeah, I am not going to plug in keyboard to random server nodes)
- store key on disk (bad security)
- hardware key (not great security, if server gets stolen, so does the key)
- network key server (leads to chicken and egg problems)
So I designed my own tool in April for this: https://github.com/fingon/sssmemvault
With it and some pyinfra hackery, I configured the new server nodes so that they have encrypted zfs datasets, which work as long as sss-memvault instances can talk with each other AND have the encryption key available in their shared state (which is kept in memory) even after restart.
However, if a node gets powered off, and restarted outside the home environment, it cannot decrypt its storage anymore. My sss-memvault configuration by design does not work across anything else than my home CIDR, so the other nodes will not chat with node that is reaching them through some other means (e.g. Tailscale). And as key can be decrypted only with help of at least one or more other nodes (SSS part), it is reasonably secure against random data theft (or device seizure). Even if whole cluster gets stolen, the sss-memvault state that is in memory is lost, and the data cannot be decrypted without manual steps to bootstrap the keys into memory of the nodes.
Kubernetes setup
Which distribution: k3s
There’s plenty to choose from, and I went for K3s. There is no substantial difference among them in my book, but it seemed good enough and is very widely used. The basic installation seemed also relatively simple although I got to iterate it number of times as especially Longhorn configuration took number of attempts to get right, and ‘nuke it from orbit’ was easier way to retry than fiddling with it by hand.
As I have two recent Mele mini nodes, that I planned to use for both control and data, and additionally frankenrouter which I plan to use only as control plane (without any workload pods, just etcd and API), it seemed reasonable enough to also configure it to use it.
I wound up passing couple of of parameters to k3s init:
'--write-kubeconfig-mode 644',
'--embedded-registry', # Enable local caching of container images
'--flannel-ipv6-masq', # ipv4 is masq by default, do same for ipv6
'--snapshotter=stargz', # enable partial pull to start
'--disable local-storage', # we want longhorn ( from Helm )
'--disable servicelb', # we want metallb ( from Helm )
# lb if I someday make it
'--tls-san kube.fingon.iki.fi',
# actual API nodes
'--tls-san fw.home',
'--tls-san mele1.home',
'--tls-san mele2.home',
(Secure) Networking: tailscale
There are various network providers for Kubernetes, but I chose to simply to route all traffic through Tailscale between the Kubernetes nodes as this is more for fun cluster, and less about optimal performance.
Configuring Kubernetes using Tailscale addresses turned out to be slightly trickier than I thought, as Kubernetes by default uses the IP address of the network interface with default route, and that is typically not the Tailscale interface. So in my first deployment I wound up with a deployment that really used the non-Tailscale IP addresses to communicate with each other even if I bootstrapped it up using IP address that is in Tailscale subnet. Probably better address selection algorithm would have preferred using address that is similar to that of the target address, instead of the one on default route interface.
Once I figured it out, it was easy enough to explicitly set the --node-ip, e.g.
--node-name mele1.home --cluster-init --node-ip 100.64.0.10
for the first node, and for rest e.g.
--node-name mele2.home --server https://mele1.home:6443 --node-ip 100.64.0.11
Storage: Longhorn
As I wanted HA storage, I considered couple of different options. Ceph/Rook, Longhorn, or something object storage based. After some study, I chose Longhorn as it seems relatively well integrated AND it works with only two storage nodes (my mini cluster has 3 nodes, but the nodes are not quite symmetric).
Longhorn requires extent support which zfs does not have, so I created ext4 zvol inside encrypted dataset on each node that I had provisioned earlier. This I provided to Longhorn as storage path and it worked fine.
Deploying Longhorn using Pulumi on the other hand was quite painful. It turns out that the default Pulumi Helm Chart implementation (e.g. helm.v4.Chart) does not handle hooks, and Longhorn relies on them. So the non-native Pulumi option helm.v3.Release which uses Helm underneath was the solution, but it took me two evenings worth of debugging to try to figure out why the Longhorn installation uninstalled itself immediately after installation.
Another interesting thing I ran at was that while Longhorn backups specify concurrency as optional value, default value is 0, and it causes the backup job to crash. Another thing I spent some time figuring out. Once I set it to ‘1’ my daily backups were fine.
With those two hurdles out of the way, (encrypted) Longhorn on top of zvol in the encrypted dataset worked finally.
Workload migration
Once I had set up the cluster, moving the (Pulumi provisioned) Kubernetes workloads from kind to the new k3s was trivial. The only painful part was that I had used really historic version of OutlineWiki backup utility cronjob, and the new image was not compatible with my paranoid configuration ( ListBuckets is not needed · Issue #42 · Stenstromen/outlinewikibackup ) but the maintainer added option for paranoid configuration and all was good again.
So what is the outcome?
Frankenrouters memory usage is less now, as it is participating only in etcd and API server roles of k3s. mele1/mele2 Kubernetes run everything kind used to do before. There is also room to grow:
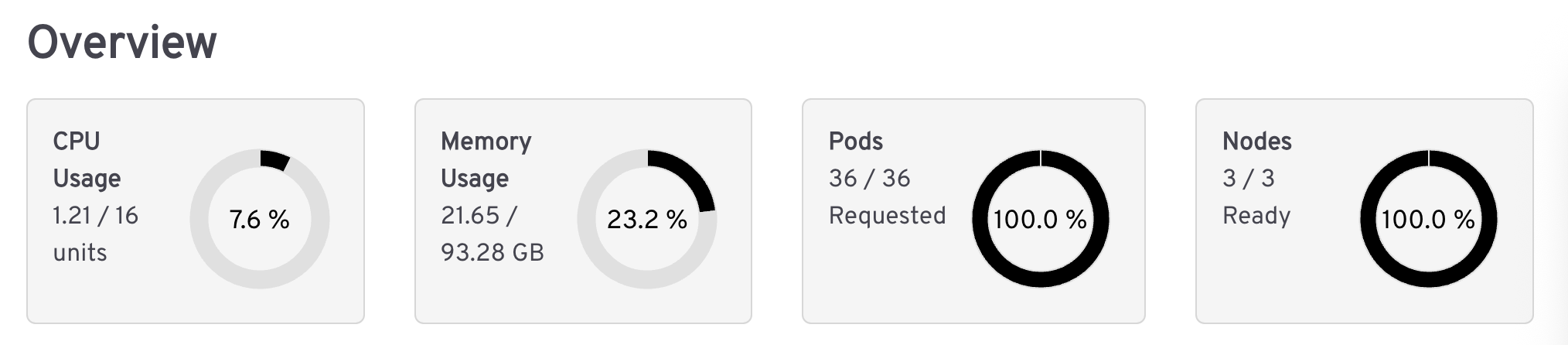
Here’s Headlamp overview of the cluster ( https://headlamp.dev/ ):
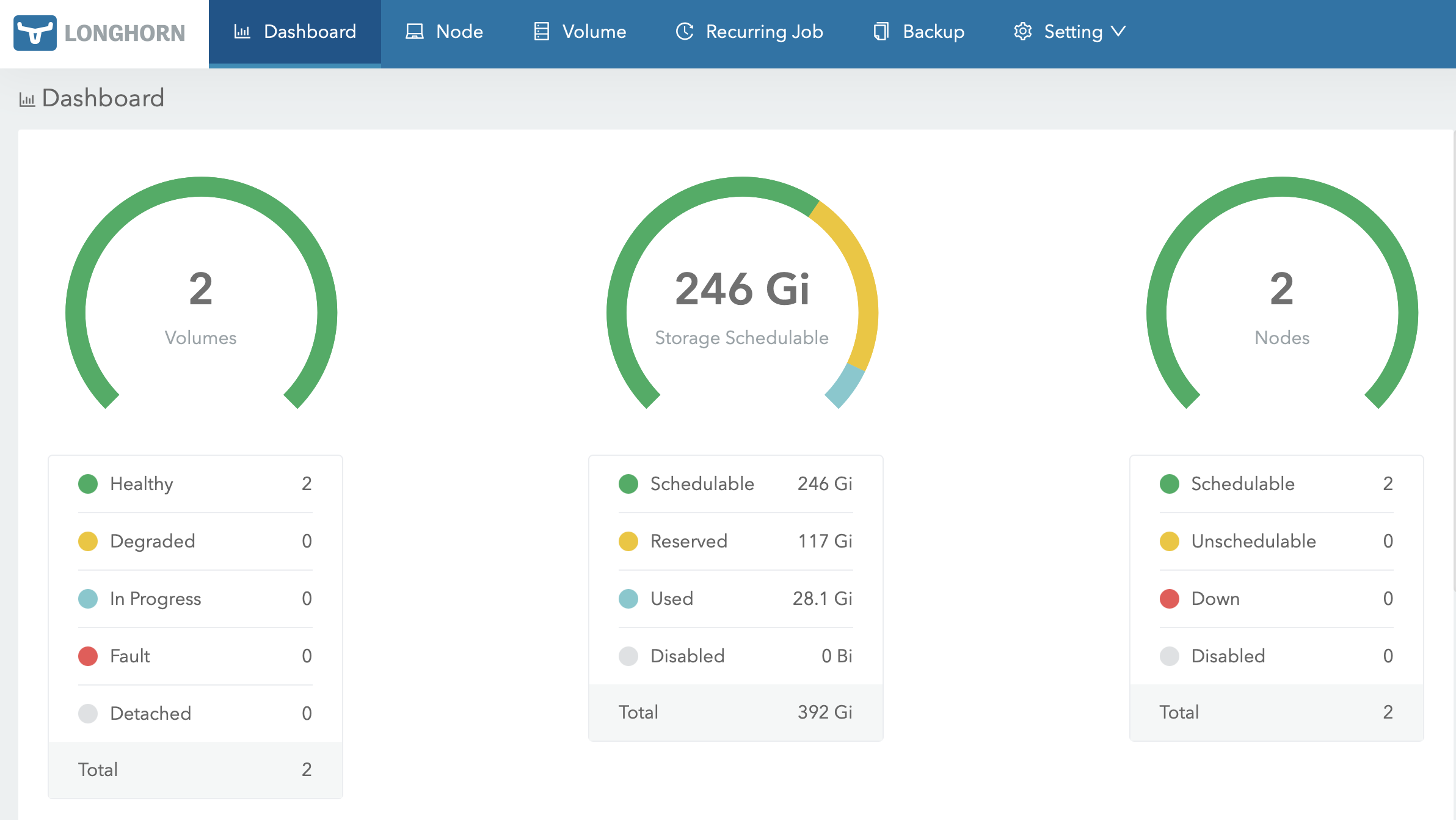
 And Longhorn overview (I gave only half of storage space of
And Longhorn overview (I gave only half of storage space of meles to Longhorn, the rest I will do something else with.)
Final remarks
I think it was interesting to set up the ‘real’ Kubernetes cluster at home, but I wonder about its utility. I like the idea of automated backups ( I configured Longhorn to automatically backup the volumes I care about and retain copies for 30 days ), and nodes being rebootable without services failing, but in practice if the frankenrouter is restarted it is not HA anyway, and without external networking the cluster is bit worthless. Setting up HA networking for the home on the other hand seems like waste of effort and perhaps not worth doing.
At least in the short term this solved the memory problem of frankenrouter. I will perhaps also shift bit more workload towards the cluster later on, as with that I can more easily restart those worker nodes without causing availability problems.
I am still happy with my hardware choice - I think Raspberry Pis are overrated compared to cheap mini Intels these days. I wish someone made ‘Mac Mini’-like ARM boxes with Linux in mind, but I have not seen one that looks competitive (in terms of pricing or performance) so far. Anyway, this is what I’ll be rolling for the time being